The post As a Data Scientist what we need to know in professional life? appeared first on Magnimind Academy.
]]>1- Python

If you were to deliver Oscars to programming languages, the most-deserving candidate would have been Python. It has been the fastest-growing and most used major programming language today. Thanks to its versatility and user-friendliness, Python can be used for almost all the steps involved in data science processes. The massive libraries of Python, which are extremely easy to learn even for a beginner in the field of data science, are used for data manipulation. Apart from being an independent platform and an open source language, Python also easily integrates with any existing infrastructure, which you can then use to solve the most complex problems in data science. Python is used by many banks for crunching data while several institutions use it for data visualization and processing. Even weather forecast companies like ForecastWatch use and leverage Python.
2- R

Once, this open source language was the primary language for data science. Though it has been replaced by Python as the leading programming language that data scientists need to know, it’s still not far behind Python. The roots of R are in statistics, and it’s still extremely popular with statisticians. Be it statisticians, data scientists, or analysts – anyone wanting to make sense of data can use R for data visualization, statistical analysis, and predictive modeling. Thanks to its open interfaces, R can easily integrate with other applications and systems.
3- Machine Learning and Artificial Intelligence (AI)

If you’re opting for a data scientist career, you should be familiar with ML (machine learning) and AI. Since the field of data science needs the application of skills in different areas of machine learning, you should learn and hone your skills in various machine learning areas and techniques like reinforcement learning, supervised machine learning, neural networks, adversarial learning, logistic regression decision trees, etc. Knowing these will help you to solve different data science problems that are based on forecasts of key organizational outcomes.
Whether you’re doing a full-time course or an intensive short-term data science bootcamp in Silicon Valley, you should also learn (in addition to the above) Hadoop, SQL, and Apache Spark. Apart from the technical skills, your professional life would also demand you to be an expert in some non-technical skills. These include having:
- Intellectual curiosity to ask questions that help you discover and prepare data;
- Business acumen to have a good knowledge of the industry you’re working in and knowing what business problems you’re going to help the company solve;
- Good communication skills to fluently and clearly translate your technical findings to a non-technical team; and
- A collaborative attitude to work in a team, which could involve product managers and designers, server and client software developers, company executives, marketers, etc.
. . .
To learn more about data science, click here and read our another article.
The post As a Data Scientist what we need to know in professional life? appeared first on Magnimind Academy.
]]>The post What exactly does Data Science mean? Is it really going to revolutionize the industry? appeared first on Magnimind Academy.
]]>1- What’s data science?
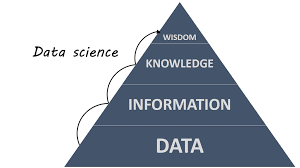
Put simply, data science can be considered as the way of extracting valuable insights from raw data. Stakeholders and business decision-makers use these insights to make critical business decisions. As the world is getting more and more connected, a huge amount of data is being generated by businesses, as well as, common people almost every moment. While a business can always collect that data but it’ll be of no use until that’s analyzed. And this is exactly where data science professionals come into the picture.
Data science involves a huge number of expertise areas and disciplines to develop a thorough, holistic, and refined approach toward raw data. Data science professionals have to be skilled in a plethora of disciplines – from math, statistics, and data engineering to advanced computing and visualizations to perform the roles effectively. While data science is a broad spectrum and there’re lots of jobs associated with it, data science professionals typically follow a workflow. Usually, the steps of such a workflow include capturing data, managing data, performing exploratory analysis, and reporting.
2- How data science can revolutionize the industry?

Applications of data science can be observed in a huge number of industries and the field has already helped us achieve some major goals which weren’t simply possible or needed a great deal of time and effort to accomplish them just a few years ago. Implementation of data science not only presents a great opportunity to make a substantial economic impact but it holds the power to revolutionize the industries as well. Here’re some ways it can do it.
- Businesses can use data science to derive actionable insights from a massive amount of data and can put that to their use. For instance, it can greatly help them to predict the future. With the help of machine learning algorithms, data science professionals can identify patterns in raw data which wouldn’t be possible otherwise and forecast future outcomes with a greater level of accuracy.
- Businesses can implement data science to review risky ideas before putting them into action actually and thus, they become able to avoid potentially costly mistakes and risks.
3- Parting thoughts

There’re lots of other ways through which data science impact almost all the industries. Some of the major ways it can revolutionize the world include bringing precision to public services, stability for businesses, a new degree of operational efficiency, and many more. And we can only expect to see the presence of data science in a more improved manner across more industries in the coming years.
. . .
To learn more about data science, click here and read our another article.
The post What exactly does Data Science mean? Is it really going to revolutionize the industry? appeared first on Magnimind Academy.
]]>The post Is it easy for Data Engineer to become Data Scientist? appeared first on Magnimind Academy.
]]>In this post, we’ve tried to outline the key differences between these two positions to help you make an informed decision. Let’s start the discussion.
1- What’s a data scientist?

Data scientists are the people who’ve got the ability to derive actionable insights from massive datasets to address specific business problems. At their core, these people analyze massive amounts of data to develop applied mathematical models.
2- What’s a data engineer?

A data engineer is a professional who focuses on preparing the data infrastructure for analysis. Their job responsibilities encompass the production readiness of data and various other things like resilience, scaling, formats, and security.
3- Skills required for each position

At their core, data engineers come from a programming background. This usually encompasses Python, Java, or Scala. These people usually have an emphasis on big data and distributed systems.
Data scientists, on the other hand, usually come from a statistics and/or applied mathematics background together with computer science. These people also need to interact with different business domain experts to cultivate the desired insights.
4- Overlapping skills between a data scientist and a data engineer
There’re various skills where both of these positions’ abilities overlap. For instance, both of them overlap on programming. However, a data scientist’s are usually well behind that of a data engineer. They also overlap on analysis. Here, a data scientist’s analytics skills are well beyond the analytics skills of a data engineer. Probably the biggest overlap can be observed when it comes to big data. A data engineer uses his/her systems creation and programming skills to develop big data pipelines. And a data scientist uses his/her advanced math and limited programming skills to develop advanced data products utilizing those existing data pipelines.
At some organizations, data scientists are tasked with doing things that data engineers should. While data scientists aren’t equipped with the skills to become data engineers, they can acquire the skills. On the other hand, it’s far less common when data engineers begin doing data science. In reality, these positions aren’t interchangeable and it may not be completely easy for a data engineer to become a data scientist. However, recently we’re seeing a new breed of engineers who’re proficient in both data science and data engineering. These people have enough experience and knowledge to work in both fields. These people are called machine learning engineers who’re cross-trained to become experts at both fields. As the bar for performing data science is decreasing gradually, we can expect to see the value of these people increasing only.
. . .
To learn more about data science, click here and read our another article.
The post Is it easy for Data Engineer to become Data Scientist? appeared first on Magnimind Academy.
]]>The post What kind of work product do Data Scientists produce? appeared first on Magnimind Academy.
]]>If you’re an aspiring or beginner data scientist, you’ve probably gone through data scientist job responsibilities published in job openings in various job boards. They mention a lot of things which may seem a little confusing to a fresh or aspiring data scientist. In this post, we’re going to discuss exactly what kind of things do data scientists produce. Let’s have a look.
While data science is quite a varied field and the duties of data scientists are widely spread, it can be said that their work is focused on producing one key thing – discovering opportunities and solutions that can help a business attain sustainable growth.
In order to discover opportunities and solutions, a data scientist needs to perform a wide range of tasks. Let’s have a look at the common tasks.
- Identifying the problems which provide the greatest opportunities to a business
- Identifying proper datasets and variables
- Gathering massive sets of structured and unstructured data from different sources
- Cleaning and validating that data to ensure uniformity, completeness, and accuracy
- Devising and implementing algorithms and models to mine big data
- Analyzing that data to identify patterns and trends
Once a data scientist has discovered opportunities and solutions, he/she needs to communicate the findings to stakeholders and colleagues, who’re not into data science, using visualization and other means.
Put simply, a data scientist is a person who makes value out of massive sets of data. Such a person fetches information proactively from disparate sources and analyzes the captured data to understand how a business performs. Additionally, data scientists often develop AI tools which automate certain processes within the organization.
The job of a data scientist comes with many definitions and it sometimes gets merged with other jobs related to the data science field. However, typically, the work of a data scientist involves producing machine learning-based processes or tools within the business, like automated lead scoring systems or recommendation engines.
Usually, the steps involved in the workflow to perform a data scientist’s responsibilities are called the data science process. This process encompasses several crucial steps. These usually include framing the problem accurately, gathering the raw data required to solve the problem, processing that raw data, exploring that data once it’s cleaned, performing in-depth analysis (this include implementing algorithms, statistical models, machine learning etc), and finally, communicating the findings of the analysis.
It’s important to understand that data science isn’t all about techniques or algorithms or programming or implementation. Instead, it’s a multi-disciplinary field which requires the practitioner to hold a concrete knowledge of translating between technology and business concerns. And that’s the key characteristic which makes the job of a data scientist so much valuable and promising.
. . .
To learn more about data science, click here and read our another article.
The post What kind of work product do Data Scientists produce? appeared first on Magnimind Academy.
]]>The post How does machine learning benefit from big data? appeared first on Magnimind Academy.
]]>Modern businesses understand the power of big data, but they also understand that it can be even more powerful when merged with intelligent automation. And this is exactly where the power of machine learning comes into the picture. Machine learning systems help businesses in a multitude of ways including managing, analyzing, and using the captured data far more strategically than ever before.
In simple terms, machine learning is a set of technologies which empower connected computers and machines to learn, develop, and improve based on their own learning through various methods. These days, all the large corporations, giant tech organizations, and data scientists are foreseeing that big data is going to make a tremendous difference in the machine learning landscape.
Inherently, machine learning is an advanced subset of artificial intelligence that learns new things from databases on its own in a programmed manner. It’s based on the idea that says machines can learn from data, find out useful patterns, and become capable of making decisions without much human intervention.
While machine learning has been around for decades, nowadays it has become possible to automatically and quickly produce models which can analyze more complex, bigger datasets and deliver more accurate results quickly – even on a massive scale. And by creating these kinds of models, a business stands a better chance of finding profitable opportunities out.

Machine learning doesn’t involve any prior assumptions. Once they’re provided with the required data, machine learning algorithms can process that data and identify patterns. Then those patterns can be used on new datasets. Generally, this technology is applied to high-dimensional datasets. It means the more data you can provide, the more accurate your predictions will be. And this is exactly where the power of big data comes in.
As the industry and sciences are experiencing a phenomenal rise in data generation, this scenario has presented a great opportunity for machine learning and big data to come together and create machine learning techniques which have the ability to manage modern data types by attaining computational and statistical intelligence for navigation of massive amounts of information with no or minimal human intervention.
Machines learn from extensive calculations performed over datasets, meaning the more the data, the more effective the learning. With the emergence of big data together with the advancements in computing technologies, machine learning has already evolved from that of the past. With the steadily increasing proliferation of big data analysis into machine learning, machines and devices will get smarter and should be able to perform in a more advanced manner. This will eventually lead to improvement and advancement in machine learning solutions.
. . .
To learn more about machine learning, click here and read our another article.
The post How does machine learning benefit from big data? appeared first on Magnimind Academy.
]]>The post 10 Information Related to Data Science Master’s Degree appeared first on Magnimind Academy.
]]>
#1. Before entering a data science master’s degree, you should ensure that you’re truly interested in what the program would entail. For example, a professional may try to find an opportunity to get some experience in working with data to gain exposure while a student may try to take a statistics class.
#2. These days, a lot of data science master’s programs are taught online which means it has become easier than ever to learn the skills required to become a data science professional. You’d be able to enjoy a lot of flexibility in terms of studying when you want, working at your own pace, picking a course schedule which suits you the best etc.
#3. Having a data science master’s degree is surely an effective way to develop data science skillsets but not a prerequisite to start your career in data science. It’s possible to step into the field without having a data science master’s degree.
#4. A data science master’s degree heavily matters when you’re applying for a position but not having a master’s degree will stop you from getting that job. For instance, some tech giants may need the applicants to have a data science master’s degree while other companies may not have those stringent criteria.
#5. While data science professionals are already in high demand, having a data science master’s degree could make your chances even better. Apart from that, you’ll be in a better position to negotiate your benefits.
#6. If you want to truly apply for a data science master’s degree, first you should decide on the pathway you want to take. If you’re willing to return to the school, obtaining such a degree can help you in defining the pathway to a good extent.
#7. Some of the data science master’s degree programs are still in the process of developing the proper curriculum which blends computer science, math, and statistics, and there’s a broad range in terms of breadth of knowledge offered, program quality etc. In addition, apart from requiring an investment of a minimum of one to two years, they can cost thousands of dollars.
#8. Some data science master’s degree programs, especially the newer ones, may risk overpromising the students and under-delivering on future employment.
#9. If you can complete a full data science undergraduate curriculum that involves statistical, computational, and professional practice aspects, it might be more comprehensive than a data science master’s degree program.
#10. If your aim is to getting a PhD, you shouldn’t look beyond a data science master’s degree program.
Final Takeaway

Probably you’ve already understood that it’ll be your call whether to go for a data science master’s degree program. Consider the above information thoroughly and make an informed decision in accordance with your future goals.
. . .
To learn more about data science, click here and read our another article.
The post 10 Information Related to Data Science Master’s Degree appeared first on Magnimind Academy.
]]>The post What are Big data analytics tools and what are the advantages of these? appeared first on Magnimind Academy.
]]>It’s important to understand that big data is of no use without the analysis of the captured information and making sense of this data falls under the domain of big data analytics tools that offer different capabilities for businesses to obtain competitive value. Big data analytics is a collection of different processes which are related to business, data scientists, production teams, business management, among others.
There’re several big data analytics tools are being utilized for big data analytics model. We’ve created this post to give you an overview of some of the most popular big data analytics tools, how they work, and why they have gained popularity.
Before delving deeper, let’s have a quick look at some features and characteristics that any big data analytics tool must contain.
1- Fundamental features of big data analytics tools

- Analytic capabilities: Different big data analytics tools come with different types of analytic capabilities like decision trees, predictive mining, neural networks, time series etc.
- Integration: Sometimes additional programming languages and statistical tools are required by businesses to conduct different forms of custom analysis. So, it’s required for big data analytics tools to come equipped with it.
- Scalability: Data wouldn’t be the same always and will grow as a business grows. With the scalability feature of big data analytics tools, it’s always effortless to scale-up as soon as the business captures new data.
- Version control: The majority of the big data analytics tools get involved in the adjustment of the parameters of data analytics models. Version control feature helps to improve the capabilities to track changes.
- Identity management: Identity management is a required feature for all effective big data analytics tools. They should be able to access all the systems and all related information which may be associated with the computer software, hardware, or any other individual computer.
- Security features: Data security should be paramount for any successful business. The big data analytics tools that are used should come with safety and security features to safeguard the collected data. In addition, data encryption is an imperative feature which should be offered by big data analytics tools.
- Visualization: This feature of big data analytics tools enables professionals to display the data in a graphical format, making it more useable.
- Collaboration: Though analysis can be a solitary exercise sometimes, it frequently involves collaboration and thus, this feature is required.
You can always go out and purchase big data analytics tools in order to cater to the needs of your business. But all big data analytics tools aren’t created equal and some may not be efficient in dealing with the task for which you’re buying it. In addition, buying additional tools beyond your business’s existing analytics and business intelligence applications may not be necessary based on the particular business goals of a project.
In this post, we’re going to take a closer look at some of the most popular big data analytics tools to help you make an informed purchase decision. Just ensure that the tool you select comes with all of the features mentioned above together with other ones that may be required to support your business results and organizational decision-making teams as well.
2- Popular big data analytics tools

Here’re some of the widely used big data analytics tools together with their key advantages.
2.1- Apache Hadoop

It’s a software framework employed for the handling of big data and clustered file system. This open-source framework offers cross-platform support and is being used by some of the giant tech companies including Microsoft, IBM, Facebook, Intel etc.
Advantages:
- Highly scalable
- Offers quick access to data
- Presence of Hadoop Distributed File System (HDFS) that comes with the ability to hold every type of data
- Highly effective for R&D purposes
2.2- Tableau Public

This intuitive and simple tool offers valuable insights through data visualization. A hypothesis can be investigated with the help of Tableau Public. You can embed visualizations published to this tool into blogs and share web pages through social media or email.
Advantages:
- Enables free publishing of visualizations to the web
- No programming skills required
2.3- Google Fusion Tables

When it comes to big data analytics tools, Google Fusion Tables is a cooler version of Google Spreadsheets. You can use this excellent tool for data analysis, large dataset visualization etc. In addition, you can add Google Fusion Tables to your business analysis tools list.
Advantages:
- Lets you visualize larger table data online
- Lets you summarize and filter across a huge number of rows
- Enables you to create a map in minutes
2.4- Storm

It’s an open-source and free big data computation system. It comes with distributed stream processing, fault-tolerant, real-time processing system together with real-time computation capabilities.
Advantages:
- Guarantees the processing of data
- Reliable at scale
- Very fast and fault-tolerant
2.5- RapidMiner

It’s a cross-platform that comes with an integrated environment for predictive analysis, data science, and machine learning. It comes under different licenses and the free version allows for up to 10,000 data rows and 1 logical processor.
Advantages:
- The effectiveness of front-line data science algorithms and tools
- Integrates well with the cloud and APIs
- The convenience of code-optional GUI
2.6- Qubole

This all-inclusive, independent big data platform manages, learns, as well as, optimizes on its own from the usage. It enables the data team to focus on business outcomes rather than managing the platform.
Advantages:
- Increased flexibility and scale
- Faster time to value
- Optimized spending
- Easy to use
2.7- NodeXL

It’s one of the best big data analytics tools available in the market. This open-source software offers exact calculations and comes with advanced network metrics.
Advantages:
- Graph visualization
- Graph analysis
- Data import
2.8- Apache SAMOA

SAMOA or Scalable Advanced Massive Online Analysis is an open-source platform for machine learning and big data stream mining. With this, you can create distributed streaming ML algorithms and have them run on multiple DSPEs.
Advantages:
- True real-time streaming
- Fast and scalable
- Simple to use
2.9- Lumify

This free and open-source tool lets you perform big data fusion/integration, visualization, and analytics. Some of its primary features are 2D and 3D graph visualizations, full-text search, integration with mapping systems, automatic layouts, among others.
Advantages:
- Scalable and secure
- Supported by a dedicated and full-time development team
- Supports the cloud-based environment
2.10- MongoDB

It’s a NoSQL database written in JavaScript, C, and C++. It comes with features like Aggregation, Indexing, Replication, MMS (MongoDB management service), file storage, load balancing, among others.
Advantages:
- Reliable and low cost
- Easy to learn
- Offers support for multiple platforms and technologies
2.11- Datawrapper

It’s one of the big data analytics tools that are used by newsrooms throughout the world. This open-source platform enables its users to quickly generate precise, simple, and embeddable charts.
Advantages:
- Works very well on every type of device
- Fast and interactive
- Fully responsive
- No coding is required
Closing Thoughts
Big data analytics tools have become imperative for large-scale industries and enterprise because of the massive volume of data they need to manage on a regular basis. These tools help businesses save a significant amount of resources and in obtaining valuable insights to make informed business decisions. As big data analytics refers to the complete process of capturing, organizing, and analyzing massive sets of data, the process requires very high-performance analytics. In order to be able to analyze such massive volumes of data, specialized software like big data analytics tools are must.
In the present situation, the volume of data is steadily increasing along with the technology growth and world population growth. This is a clear indication of the immense necessity of having big data analytics tools for businesses to leverage the power of that data. These tools are being heavily used in some of the most widespread sectors including travel and hospitality, retail, healthcare, government, among others.
With huge investments and interests in big data technologies, professionals with big data analytics skills are in high demand. For those looking to step into this field, probably this is the best time to get some certifications to showcase their skills and talent. It’s important to note that the domains of the big data landscape are quite different and so does their requirement. Since data analytics is the emerging one in every field, the need for trained professionals with adequate knowledge is naturally huge as well.
. . .
To learn more about data science, click here and read our another article.
The post What are Big data analytics tools and what are the advantages of these? appeared first on Magnimind Academy.
]]>The post Data scientist and their future is seen bright for job analysts appeared first on Magnimind Academy.
]]>1- An overview of the skills needed to become a data scientist

Typically, data scientists have a solid understanding of software development, database systems, predictive analysis, and statistics. This makes the role somewhat different that needs the skills of both a statistician and a computer scientist and this is the main reason why data scientists are experiencing high demand.
At its simplest form, data science revolves around the collection, storage, and analysis of huge amounts of data. In the entire process, data scientists make use of a lot of advanced tools and technologies that help them to a good extent in performing their activities. For example, advanced solutions like artificial intelligence, machine learning, powerful analytics tools etc enable them to process and understand huge volumes of data at unprecedented speeds. Data scientists are also the person responsible for translating the insights for other people in the organization, including stakeholders and senior executive – decision-makers in short. For example, they may decide on the form of data that is needed to be filtered into a storage system or pass details about consumer behavior on to other departments for building more successful and targeted campaigns.
Now consider the fast pace at which more-advanced and diverse tools and technologies in the field of data science are emerging. What we can learn from all these is how different this industry will be in the coming future. Probably you are already aware of the fact that the job of data scientists has already been considered as the 21st century’s sexiest job. And these days, job analysts across the globe are strengthening the statement as well. But how are they predicting this? What are the probable reasons? Let’s explore.
2- Why the future of data scientist is extremely bright

Most of us have gone through some articles portraying that the field of data science is already saturated. While it’s a fact that there is a huge number of data scientists are working in the field and a lot of aspirants are waiting to join the league, but that isn’t going to impact the promising future of data scientists anyway. Despite all those noises, there are no real reasons to believe that there’ll be a paucity of jobs for skilled data scientists. In fact, the very arguments utilized to form those statements are actually the reasons not to worry at all. Let’s have a look at the reasons for which the future of data scientists seems to be bright.
2.1- An exponential growth of data volume

A huge amount of data is being generated by both businesses and common people on a regular basis. A recent study reveals that the number of consumers that interact with data daily will be a whopping 6 billion by 2025. In addition, in 2018, the amount of total data in the world was 33 zettabytes and now this is projected to become 133 zettabytes by 2025. As the world is becoming more and more connected than ever through the increasing use of connected devices, data generation will keep on rising. And data scientists will be central in helping businesses leverage that data effectively.
2.2- Increased commoditization

It’s evident now that a significant number of tasks performed by data scientists is getting commoditized increasingly – a huge number of machine learning frameworks now come with libraries that contain off-the-shelf models which are pre-trained, pre-architectured, and pre-tuned. The resulting effect is that a well-rounded data scientist is now able to solve in a much shorter timeframe what an entire time wasn’t able to solve in several months a decade ago. It means that hiring a well-rounded data scientist has become viable for a significant number of domains for which the idea was too complex or too expensive before. Tools and technologies will keep on appearing and disappearing, but they’ll be targeted at increasing the productivity of data scientists and thus, their net value to a business.
2.3- The field is still evolving

It’s a fact that any field without growth potential becomes stagnant at some point in time. It also indicates that the jobs within those fields need to change in order to stay relevant, but that isn’t the case with the data scientist job. Since there is no sign of slowing down with a significant number of opportunities gearing up to appear, probably it’s the best time for people looking to become data scientists to start preparing. Of course, there’ll be some probable minor changes like someone working in the position of a data scientist in an organization may not be doing the same thing at another company. In a way, it’ll be helpful for aspiring data scientists as they’ll be able to focus on learning more specialized skills and do what’s most meaningful to them.
2.4- The emergence of data privacy regulations

You may already know that in the European Union, the GDPR (General Data Protection Regulation) took effect in May 2018 for countries. This implementation increased the need for data scientists to the organizations because of the need for storing data responsibly. One major aspect of the GDPR is that it allows consumers to ask the companies to delete some sorts of data. These days, people have become increasingly conscious about their online privacy and security and thus, they consider different aspects of giving away their personal information before actually doing it. They now understand what can be the probable consequences of the occurrence of a data breach. As a result, it has become impossible for companies to handle customer data irresponsibly. In addition, the GDPR is probably just the beginning with some more privacy rules pertaining to consumer data waiting to be implemented. In this scenario, data scientists are the best people who can guide the businesses on adhering to those regulations while leveraging the power of that data.
2.5- The task of leveraging the power of data is complex

Businesses may have the opportunities to capture a massive volume of data regarding website interactions, customer transactions etc from different sources. But what if they aren’t in a position to store, analyze, and derive insights from that data? Simply, the data is of no use. And that’s exactly where data scientists come into the picture. Equipped with huge skillsets, these trained professionals only can help the businesses to get a competitive edge and accomplish their business goals. As we’ve already discussed that the increasing use of high-end devices will result in a more connected world where more amount of data will be generated on a regular basis, the scenario will become even more complex without the help of data scientists. And for data scientists, it’ll be something like an ongoing opportunity.
3- Closing thoughts that every aspiring data scientist should consider

While the above points demonstrate the key factors that will be instrumental in making the future for data scientists bright, aspiring data scientists also need to focus on some crucial things. First of all, there’s no denying that now there is a steady supply of average data scientists to the industry who can surely perform at a good level but may not be able to reach the exceptional mark. And to become a top-notch data scientist, you’ve to prepare yourself through the best way possible. Second, the industry will become competitive at some point of time in future, so it’s better to start planning now to rise above the competition.
Assuming you’ve your fundamentals right, you need to decide on the avenue you’ll be taking to become a good data scientist wisely. There’re a significant number of options available out there like self-learning, traditional way, bootcamps etc. All of them come with their own pros and cons. However, there’re some factors that differentiate a bootcamp from other avenues. For instance, if you’re ready to become a data scientist the hard way, joining such a program would be your best bet. There, you’ll be able to learn the concepts, tools, and technologies that are only applicable to real-life business issues and that too in a much shorter amount of time and from professionals working in the industry. In addition, most of the bootcamps offer job assistance after successful completion of the programs, so stepping into the professional field shouldn’t be an issue. But again, if you notice, we’ve mentioned the term ‘hard way’ because, from a data science bootcamp, you’ll only get what you’ll be putting in during the program in terms of time, effort, and diligence.
. . .
To learn more about data science, click here and read our another article.
The post Data scientist and their future is seen bright for job analysts appeared first on Magnimind Academy.
]]>The post Data Scientist is better than Financial Analyst, Data Analyst and Research Analyst appeared first on Magnimind Academy.
]]>1- Who’s a data scientist?

Even a decade ago, data scientists weren’t a hot property that they have become today. Perhaps the change in their fortunes signals how times have changed. This could be attributed to the massive amount of data that’s getting generated almost every second today. And with the emergence of big data, companies and businesses too have changed their views on how they see data and even the ways they can leverage the pile of data that they have been sitting upon for quite some time now. After all, the data businesses collect these days or the ones their existing and potential customers willingly share via their website, special campaigns, social media accounts, etc. make up a bulky mass of unstructured information. No business worth its salt can ignore or forget this data anymore as it’s nothing short of a virtual gold mine that can bring several benefits their way and give their revenue a significant boost. But it will happen only when someone digs into this pile of massive data and discovers business insights that no one considered looking for before. And this is where the data scientist comes into the picture.
As these people have an intense intellectual curiosity and are deep thinkers, they interpret this data and try to draw useful insights from them. From making new discoveries and asking new questions to learning new things, data scientists are driven their originality and creativity to solve complex problems and indulge in their curiosity constantly. Thus, data scientists don’t just make an observation with the complex reads from data. Rather, they seek to uncover the “truth” that lies hidden underneath the surface. For these professionals, problem-solving isn’t merely a task. Rather, it’s an intellectually-stimulating trip to find a solution. Thus, you will find data scientists designing and building new procedures for data modeling, and production utilizing algorithms, prototypes, predictive models, custom analysis etc to decode data and gather useful insights, which are then presented to tell a story to the stakeholders. These decision-makers can then use this insight to make data-driven, timely decisions that will help them take on challenges, if any, be better prepared to stay ahead of the competition, and even improve their bottom-line significantly. No wonder why Harvard Business Review called data scientist the 21st century’s sexiest job.
Now that you have an overview of who a data scientist is and what kind of role he/she plays, let’s try to find what makes these professionals better than others working with data such as data analysts, financial analysts, and research analysts. But before we do that, it’s important to take a closer look at what roles these professionals play.
2- Who’s a data analyst?

Along with data scientists, data analysts too are in high demand. Together, they are often called as DSA (data science and analytics) job. According to Forbes, DSA job listings are expected to grow by almost 364,000 listings to touch the mark of approximately 2,720,000. Just like data scientist posts, those for data analysts too aren’t the easiest positions to fill. Perhaps this explains what Forbes says about DSA jobs – they remain open for an average of 45 days, which is five days more than the market average.
The role of a data analyst is the one that people often confuse with a data scientist. It’s true that professionals in both these roles have a similarity as they work with data. Yet, the main difference between them arises based on what they do with the data.
A data analyst’s primary role is to assemble, categorize, and study data to offer business insight. Typically, data analysts are concerned with cleansing, aggregating, managing, and abstracting data in addition to conducting a variety of analytical studies on that data. Here’s a peek into some of these responsibilities that would help you know what they actually mean:
- Cleansing: This refers to the procedure of checking data accuracy and quality by recognizing and then removing biased or incorrect data from a database.
- Aggregating: This is the compilation of information from multiple data sources to organize combined datasets for data processing.
- Managing: This involves planning data processes as well as executing and maintaining them to ensure safe storage of data and information assets.
- Abstracting: It’s the process of removing a dataset’s characteristics to reduce it to a set of essential characteristics, which in turn would help in more efficient data processing.
By leveraging additional software engineering and ML (machine learning) skills, a data scientist builds upon a data analyst’s core competencies. Thus, you will find data scientists actively exploring unique ways to use existing and new algorithmic, statistical, predictive, artificial intelligence (AI), and machine learning (ML) tools and techniques to discover valuable and significant patterns in data and convert these into information for the company or organization.
Perhaps you now understand that though the two job titles and even some roles may be deceptively similar, being a data scientist is better than being a data analyst.
3- Who’s a financial analyst?

A financial analyst is responsible for collecting and organizing financial information followed by its analysis after which S/he would create presentations and offer recommendations, which will get shared with a company’s clients or the stakeholders.
The primary responsibility of financial analysts is to create financial models that can forecast the result of specific business decisions. To do this the right way, these professionals need to collect a large pile of financial data while also considering factors such as earlier transactions having a similar nature, financial market trends, etc. Based on where a financial analyst works, his/her role can differ a lot. For example, a financial analyst working in an investment bank will be much more focused on helping with deals and mergers while the one working for an insurance company would be more concerned with the risks involved in different lines of insurance, how they would affect premiums, etc.
The difference between a financial analyst and a data analyst is that the former works with large number of datasets that come from a wide range of sources such as customers, operations, safety etc. and analyzing them and turning them into recommendations and takeaways for management or clients. The main difference between a financial analyst and a data analyst is that while the former only works with financial and accounting figures, the latter works with a wide variety of numbers from diverse industries.
Perhaps this gives you a clearer picture of why being a data scientist is better than being a financial analyst.
4- Who’s a research analyst?

This is a professional who is responsible for researching, examining, interpreting and presenting data related to operations, markets, economics, accounting/finance, customers, and other information related to the field s/he works in. Typically, a research analyst is extremely analytical, quantitative, and logical apart from being adept in handling data.
Almost every industry engages research analysts though they are more commonly found in some specific industries like the financial services industry, retail industry, etc. A broad job category is covered by the research analysts, especially in the areas of operations research, market research, and industry research. The role of an operations research analyst is to study particular aspects of an organization’s business processes and work out means to improve them. For a market research analyst, the responsibilities include studying the markets to help businesses understand what kind of demand exists for services or products. For an industry analyst, the job entails researching on a specific company or specific industry in addition to keeping track of new developments and trends in an industry. In brief, the key responsibility of a research analyst is to research and find ways to improve the operations of the business or company s/he is involved with.
Thus, the role of a research analyst is limited as compared to that of a data analyst. And since it’s better to be a data scientist than a data analyst, you can infer that the post of a data scientist is much more coveted than that of a research analyst.
. . .
To learn more about data science, click here and read our another article.
The post Data Scientist is better than Financial Analyst, Data Analyst and Research Analyst appeared first on Magnimind Academy.
]]>The post What are the differences between data scientist and data engineer? appeared first on Magnimind Academy.
]]>Recently, a lot has been discussed and written about the differences between various roles in the domain of data science. Among others, the ones that have got the spotlight on them are those that discuss and debate the differences between data scientists and data engineers. If you are wondering what triggers this tremendous interest in these roles, a change in perspective that has been felt over the years could be the driving factor.
If you step back a couple of years ago, you will find that the predominant focus was on retrieving precious insights from data. As companies and organizations started making data-based and data-driven decisions, which brought several benefits their way, the significance of data management started to sink in the industry – slowly but surely. This also made the interested parties realize that the quality of data was important to derive useful insights because it’s the principle of “Garbage In, Garbage Out” that works in the domain of data science too. Even if you are capable of creating the best models, your results are likely to be weak and ineffective in case your data isn’t qualitative. And this was what brought the role of the data engineer under the spotlight.
According to Gartner, merely 15% of big data projects ever make their way into production. According to domain experts, one of the chief reasons behind such failures is due to the inability to build a production pipeline, which is one of the principal tasks of a data engineer. In the modern age of analytics, data scientists get most of the spotlight and attention. However, the roles played by data engineers are equally important, though they are often overlooked. It’s important to realize that data science (and even data analytics) would fail to flourish if no data engineering workbench exists. If you don’t believe it, you can consider what Glassdoor’s records say.
According to Glassdoor’s data in 2018, the number of job openings earmarked for data engineers was almost five times more than that for data scientists. Elsewhere, one may find data scientist jobs exceeding the number of data engineer jobs though some say it could be because numerous organizations don’t always (or are unable to) draw a distinct line between a data scientist and a data engineer. Thus, they end up posting jobs for the former whereas in reality, the jobs should have been seeking data engineers instead. Such actions on the part of organizations are perhaps triggered by their ignorance of the significant differences between data scientists and data engineers. Many reports have revealed that the majority of organizations require more data engineers than data scientists on their team. So, the question comes to this – what exactly is data engineering and how’s the role played by a data engineer different from that played by a data scientist.
Let’s dig a little deeper to answer the questions and find out the differences between data scientists and data engineers.
1- Who is a data engineer?

S/He is a professional with specialized skills in creating software solutions around Big Data.
Another way of defining a data engineer is that s/he is an inquisitive, skilled problem-solver, who loves both data and creating things that are useful to others. Thus, along with data scientists and business analysts, data engineers form an integral part of the team effort that converts raw data in ways which offer organizations useful insights and provides them with the much need competitive edge.
To understand what the role of a data engineer is, it can be said that this professional is someone who builds, develops, evaluates and maintains architectures like databases and large-scale processing systems. In contrast, a data scientist is someone who cleans, organizes, and acts upon (Big) data.
It’s the job of data engineers to suggest and at times, even implement ways to improve data quality, efficiency, and reliability. To handle such tasks, they need to utilize a range of tools and languages to blend systems together or try to track down opportunities to get hold of new data from other systems, which can help system-specific codes, for example, to act as the basic information in advanced processing by data scientists.
A data engineer will also need to make sure that the architecture that’s in place is capable of supporting the needs of the data scientists as well as the business/organization and its stakeholders.
In order to deliver the required data to the data science team, it will be the responsibility of the data engineers to develop data set processes for data mining, modeling, and production.
2- Key differences between data scientists and data engineers

With respect to skills and responsibilities, you’ll find considerable overlapping between data scientists and data engineers. One of the key differences between data scientists and data engineers is the area of focus. For data engineers, the emphasis is on creating architecture and infrastructure for data generation. On the contrary, the focus of data scientists is on advanced statistical and mathematics analysis on that generated data.
Though the role of data scientists demands a constant interaction with the data infrastructure that the data engineers have created and maintained, the former isn’t responsible for that infrastructure’s creation and maintenance. Rather, they can be called the internal clients, whose job is to perform high-level business and market operation research to spot trends and relations, which in turn need them to use an array of sophisticated methods and machines to interact with the data and act upon it.
It’s the job of data engineers to provide the necessary tools and infrastructure to support data analysts and data scientists so that these professionals can deliver end-to-end solutions for business problems. Data engineers are tasked with creating high performance, scalable infrastructure that helps deliver business insights with clarity from raw data sources in addition to implementing complex analytical projects where the emphasis is on gathering, evaluating, managing, and visualizing data along with developing real-time and batch analytical solutions.
Perhaps you now understand that despite some key differences between data scientists and data engineers, the formers depend on the latter. While data scientists deal with advanced analysis tools like Hadoop, R, advanced statistical modeling, and SPSS, the focus of data engineers remain on the products that support such tools. Thus, a data engineer may deal with NoSQL, MySQL, SQL, Cassandra, etc.
In a way, you can say that in the data value-production chain, the role of data engineers is akin to the plumbers since they facilitate the job of data scientists, data analysts and other professionals working on the fed of data science. As with any infrastructure, plumbers don’t get the limelight, and yet, they are irreplaceable since nobody can get any work done without them. The same applies to data engineers as well.
3- Language, tools, and software used by data engineers

Due to the difference in their skill sets, differences between data scientists and data engineers translate into the use of different tools, languages, and software use.
For data scientists, common languages in use are Python, R, SPSS, Stata, SAS, and Julia to construct models. However, Python and R are the most popular tools without a doubt. When these data science professionals are working with Python and R, they often resort to packages like ggplot2 to make remarkable data visualizations in R or opt for the Pandas (Python data manipulation library). There are several other packages that can come for them, which include NumPy, Scikit-Learn, Statsmodels, Matplotlib, etc. The data scientist’s toolbox is also likely to have other tools like Matlab, Rapidminer, Gephi, Excel, etc.
The tools that data engineers often work with include Oracle, SAP, Redis, Cassandra, MongoDB, MySQL, PostgreSQL, Riak, neo4j, Sqoop, and Hive.
Languages, tools, and software that both the parties have in common are Java, Scala, and C#.
One of the key differences between data scientists and data engineers emerges from the emphasis given on data visualization and storytelling, which gets reflected in the tools these professionals put to use, some of which are mentioned above.
4- When organizations get the roles wrong

As mentioned before, several organizations fail to distinguish the key differences between data scientists and data engineers and often task the former with the job that the later is specialized to do. For example, asking data scientists to create a data pipeline, which is the job of a data engineer, would mean making the former function at just 20-30% of their actual efficiency. So, it becomes important to know the differences between data scientists and data engineers and hire each for roles specifically designed to match their skill sets.
. . .
To learn more about data science, click here and read our another article.
The post What are the differences between data scientist and data engineer? appeared first on Magnimind Academy.
]]>